Сбор семантического ядра через программу Key Kollector
Рассмотрим порядок действия на примере сайта tea-coffee-opt.ru.
Сначала составляются основы для парсинга. Основа для парсинга – это
слово или словосочетание, которое лежит в основе всех нужных вам
запросов. Например, если вам нужно получить запросы вида:
- черный чай;
- зеленый чай;
- чай пуэр;
- чай цейлонский,
то основой для сбора таких ключевиков будет «чай», так как оно присутствует во всех этих запросах.
Рассмотрим несколько вариантов сбора в зависимости от поставленных задач.
Вариант 1. Глубокий парсинг для нахождения возможных вариантов категорий каталога
Таким путем стоит идти только тогда, когда от вас требуется собрать ядро
подчистую и настолько глубоко, чтобы выявить практически все возможные категории и подкатегории каталога, о которых мы можем даже не догадываться.
Обычно это бывает в случаях, когда сайт только создается и вы сами еще не знаете, какие
категории должны быть на вашем сайте.
Для сайта с тематикой чая основой для парсинга в этом случае будет слово «чай».
Key Collector на такое общее слова соберет огромное количество ключей, в том
числе и нецелевых. На чистку такого ядра уйдет немало времени.
Но даже при парсинге основы «чай» мы не сможем собрать
полное семантическое ядро. От нас ускользнут такого рода запросы, где
слова «чай» отсутствует, например: «пуэр оптом», «каркаде купить»,
«фиточай цена» и проч. Поэтому помимо основы «чай» нам
нужно подобрать другие основы, которые тоже соберут наши целевые
запросы. Для вышеперечисленных ключевых слов это:
- пуэр
- каркаде
- фиточай
Вариант 2. Парсинг по конкретным категориям
Теперь рассмотрим вариант, когда мы четко понимаем, какие категории в
каталоге должны быть, и поэтому нам не нужно искать возможные
дополнительные варианты. Тогда мы отталкиваемся от самих категорий и
собираем основы только для них.
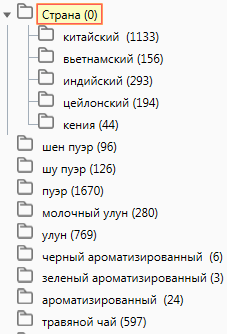
Определяем категории, для которых будем собирать семантику.

Подбираем категории
Подбираем основы для каждой категории:
- молочный
улун - улун
- шу пуэр, пуэр зеленый
- шен пуэр, пуэр черный
- пуэр
- черный ароматизированный чай
- зеленый чай ароматизированный
- ароматизированный
чай - травяной
чай, чай трава - фиточай
- вьетнамский
чай, чай вьетнам - кения
чай, кенийский чай - каркадэ
- мате
- ройбуш
- черный
чай - зеленый
чай - красный
чай - белый
чай - желтый
чай - связанный
чай - жасминовый
чай - чай
- чай
оптом
Обратите внимание на порядок запросов – им определяется очередь
парсинга. Это важно соблюдать. Таким образом, вы избавите себя от
лишней работы в будущем на других этапах.
Мы видим, что более частные основы в списке предшествуют общим. Так
«молочный улун» идет прежде «улун». Это
сделано для того, чтобы сбор осуществлялся сначала на «молочный
улун», а потом на «улун». Если будет наоборот, то
при парсинге «улун» запросы на «молочный улун»
уйдут в общую папку «Улун», и вам придется их туда
доставать и перетаскивать в отдельную папку «Молочный улун».
Именно поэтому общие основы, такие как «чай», стоят в самом
конце очереди на парсинг.
Подготовка к сбору в программе Key Collector
Key
Collector
имеет замечательную возможность запускать одновременный
парсинг сразу в несколько папок. Для этого их требуется заранее
создать.
Далее
закидываем наши основы для парсинга в очередь на парсинг в нужную нам папку. Для
этого нажимаем кнопочку сбора через Ворстат

и
выбираем галочку «Распределить по группам»
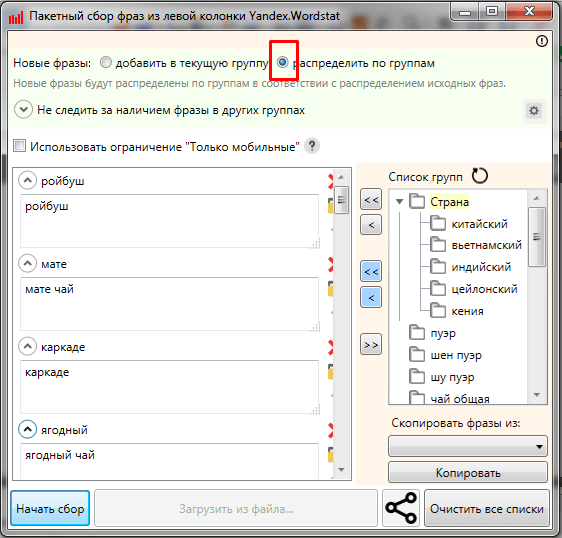
Дважды
щелкаем по каждой папке и закидываем каждую основу в появившееся
окошки.
ВАЖНО!!!
Не забудьте поставить галочку на «Не добавлять фразу, если она
уже есть в любой другой группе»
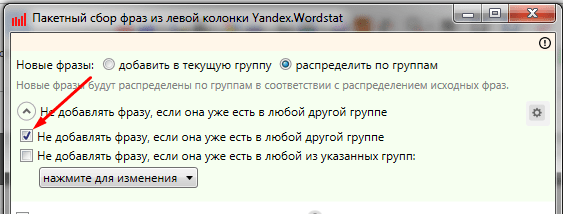
Нажимаем
«Начать сбор». Сбор займет достаточное количество
времени, поэтому можно заниматься другими делами.
Далее
чистим каждую папку от всякого рода шлака.
Чистка списка запросов
Начинаем
чистить с самой общей категории. Она наверняка собрала наибольшее
количество запросов. В нашем случае это папка «Чай». Для
начала почистим эту папку от тех слов, которые будут являются
минус-словами для любой нашей папки. Например, такие слова как
«чашка», «заваривать», «как»,
«способы» и проч. Чаще всего такие слова содержат не
нужные нам информационные запросы. Их не следует совсем выкидывать. Лучше создать для них отдельную папку «Инфо-запросы» и воспользоваться ими, когда настанет этап работы с информационным разделом сайта.
Для
начала чистки создадим папку в минус-словах и назовем ее «Общие
минусы».
Кликаем
дважды по названию
В
Key
Collector
есть удобный инструмент для чистки от минус-слов.
В
открывшемся окне проходим глазами по списку и отмечаем галочкой
ненужные нам слова, встречающиеся в запросах.
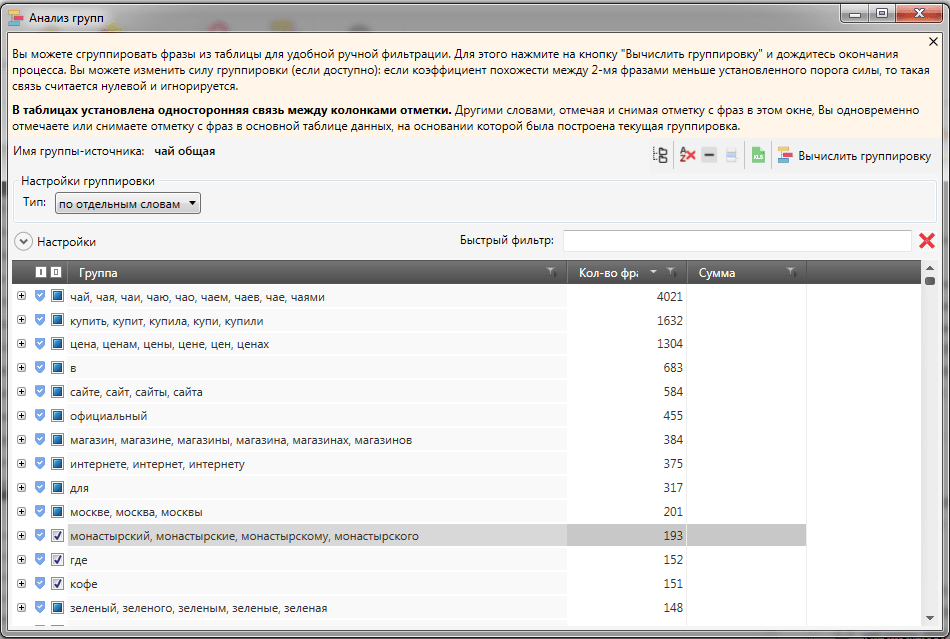
Это
самый утомительный процесс в чистке. Нужно быть внимательным, чтобы
ничего не пропустить и не выкинуть лишнее.
Если
вы сомневаетесь, является ли слово целевым, вы можете раскрыть вкладку и
посмотреть, в каких запросах это слово встречается. Возможно, это
поможет вам определиться.
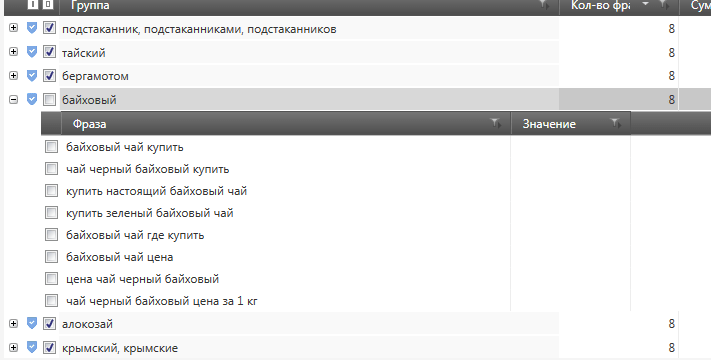
Если
мы не собираем ядро под Директ, то достаточно дойти до слов, которые
встречаются в менее чем трех фразах и остановить минусацию. Если
минусация делается для контекстной рекламы, то нужно пройти все до
конца.
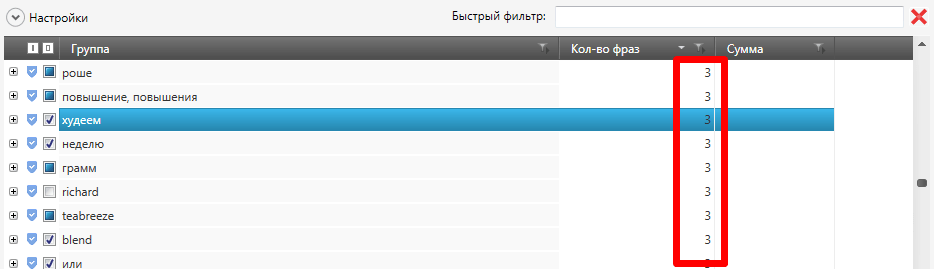
Итак,
мы прошлись по списку минус-слов и отминусовали всё ненужное. На весь
процесс поиска и отметки минус-слов ушло около 25 минут. В паке, которую я
чистил, находилось более 4000 ключей. Чистка осуществлялась до тех
слов, которые встречаются в 3 фразах.
Далее
кликаем правой кнопкой мыши по любому слову, отмеченному галочкой и
выбираем «Отправить все слова из определений целиком отмеченных
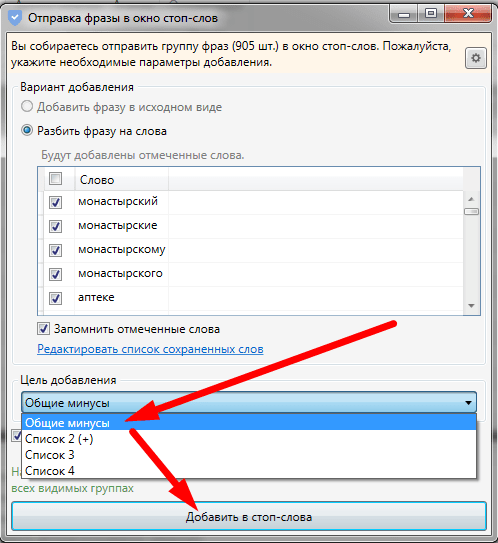
в окно стоп-слов».
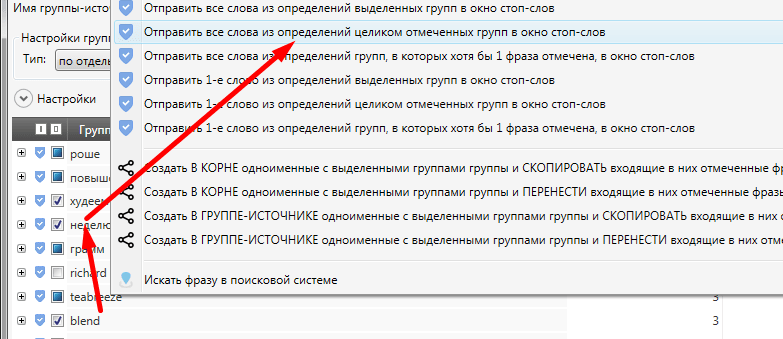
В
появившемся окне выбираем созданную ранее папку минус слов «Общие
минусы» и жмем кнопку «Добавить в стоп-слова». Это
приведет к двум действиям:
- выделенные
нами минус-слова перетекут в папку «Общие минусы»; - запросы,
содержащие минус-слова будут выделены галочкой в общем списке
запросов, и мы сможем легко их перекинуть в «Корзину».
Не
стоит запросы с минус словами удалять из проекта, так как они могу
пригодиться по разным причинам. Нужно просто переместить их в
«Корзину».
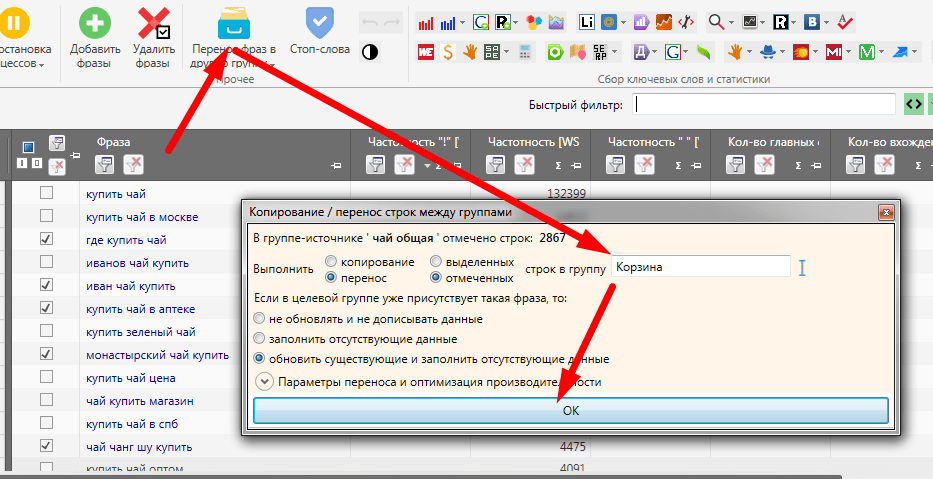
Просматриваем
быстро глазами «Корзину» на предмет того, не выкинули ли
мы случайно в нее нужные нам ключевики. Я увидел, что в отправил в
корзину фразы, которые могут пригодиться в продвижении – это
фразы со словом «где».
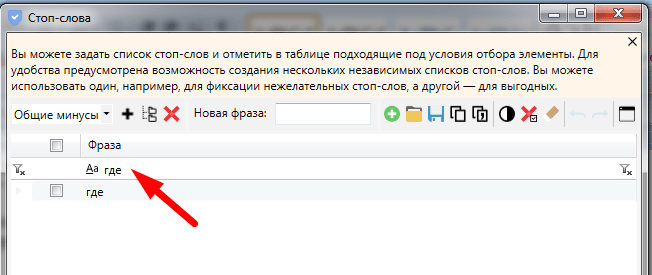
Слово
«где» в таком случае стоит убрать из списка стоп-слов.
Найти нужное слово в списке минус-слов можно через строку поиска.
Переносим фразы со словом «где» назад в папку «Чай» и
применяем заново на папку фильтр минус-слов, так как вместе с словом
«где» переехала часть ненужных нам фраз.
Чистим от минус-слов каждую конкретную папку
Теперь у нас есть «базовый» список минус-слов для чайной
тематики, и мы можем его применить для каждой папки, чтобы не чистить
их от одних и тех же постоянно встречающихся стоп-слов.
После этого чистим каждую папку индивидуально, так как общий список минус-слов
«Общие минусы» содержал только общие стоп-слова и в нем
отсутствовали минус-слова характерные только для конкретной папки.
На
полную чистку и сортировку всех категорий с распределением более
частных запросов по их подкатегориям (в запас) ушло около
3 часов.
Всего
в данном ядре:
- запросов
– более 15 000 шт - целевых
категорий – 29 шт - запасных
подкатегорий – 45 шт
Время,
затраченное на чистку и сортировку ядра – 3
часа.
Совет! При сборе ядра и обилии папок мы рекомендуем отмечать цветами папки согласно поставленным задачам для данной папки.
Пример возможных цветовых пометок групп в Key Kollector.
- Зеленый
— готовые группы, их можно переносить в Ексель; - Светло-голубой
— запасные запросы, под которые можно сделать дополнительные посадочные страницы на сайте; - Красный
– НЧ запросы по теме, на которые не стоит делать
отдельные страницы; - Оранжевый
— инфо группы, можно переносить в Ексель; - Сиреневый
– группа уже перенесена в Ексель.
Сбор частоты и Key
После
того как мы осуществили полный сбор семантического ядра для каждой
категории, нам нужно собрать данные по каждому запросу. В компании IntelOptima мы обычно собираем следующие Key:
- точную
частоту в «!»; - кол-во
главных страниц; - количество
вхождений запроса в заголовок.
Последние
два собираются по кнопке SERP
– Получить данные для ПС Яндекс.